Chatting with Libby Tilley (English Faculty Librarian) yesterday, we got on to the topic of how students know what Libraries they have access to. On joining the university, undergrads are assigned a University Library number, but they also need to register with their College and Departmental Libraries.
Things being as they are, various policies relate to who can do what in which library (more on this in another post!). As I understand it, most departmental libraries allow anyone with a University Library card to use the Library for reference purposes, but College libraries are only open to members of that College (?). Members of certain departments, or students taking particular Subjects, may also be eligible for membership of Libraries outside their 'home' department. And so on...
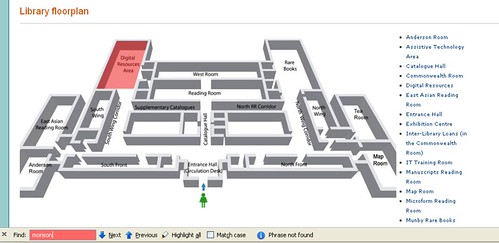
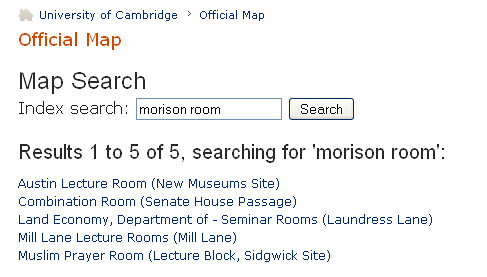
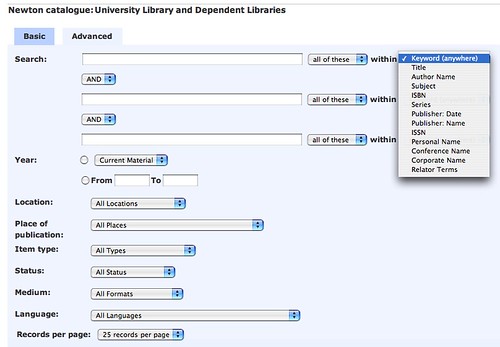
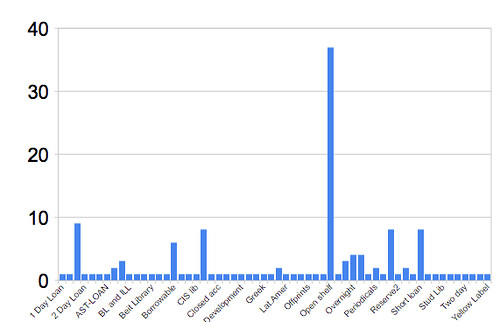
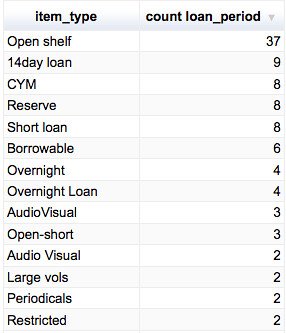
Reflecting the complex nature of the Cambridge Library scene, the organisation of the OPAC is non-trivial. Looking on the Library homepage, we see links to 8 Voyager catalogues (
University Library and Dependent Libraries,
University Library Manuscripts and Theses,
Departments and Faculties A-E,
Departments and Faculties F-M,
Departments and Faculties O-Z,
Colleges A-N,
Colleges P-W,
University of Cambridge Affiliated Institutions).
(A side effect of this organisation is presumably the requirement that any updates to the system need to be applied eight separate times?)
There is also a link to a
Universal Catalogue which I
think represents a federated search over the independent Voyager installations.
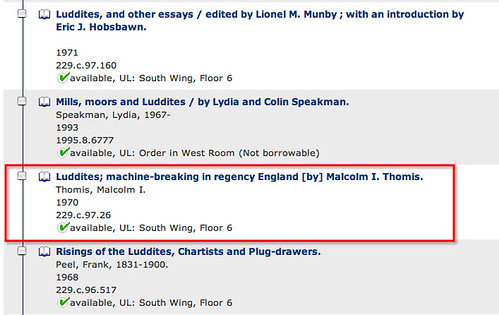
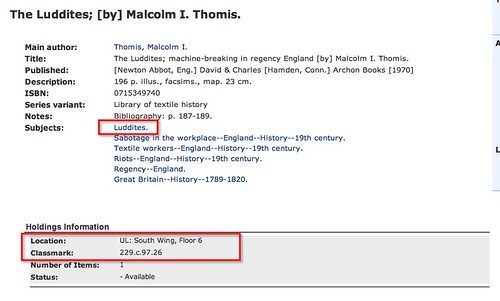
Looking at a universal search result on Newton for a likely held book, you are presented with results of the form:
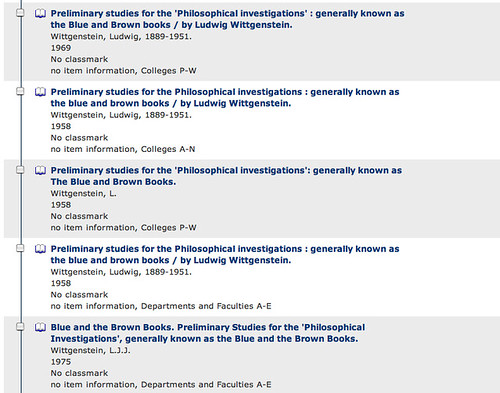
Finding which actual library holds the book, what it's status is (on shelf, or out on loan, for example), whether I (currently) have membership/borrowing rights in that library et cetera is none trivial (= lots of clicks).
So the question now arises:
- where can I browse just "a copy" of the Preliminary Studies for Philosophical Investigations (assuming I don't need a particular edition.translation)? i.e. supposing I just need to refer to it in a library and not borrow it;
- where can I borrow that work from *now* (i.e. where is it available for loan in a library I am a member of), and for how long?
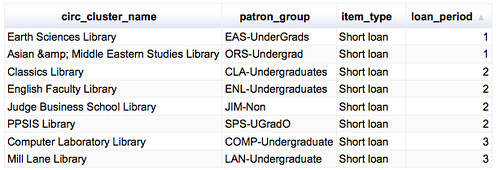
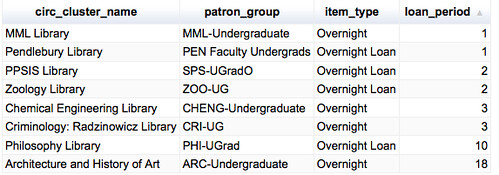
- where can I borrow it from for an extended period (which may require recalling it from a library with a generous loan period bearing in mind which libraries I have access to)?
And this, it seems to me, is an ideal scenario for a mobile application, which I'll define in general terms as one that I can refer to while at a reading desk in a library via my phone.
So what does this app need to be able to support?
- I need to declare who I am, so it can look up what Libraries I'm a member of; [as previous Arcadia Fellow
Huw Jones pointed out, this functionality exists in the Library Facebook app (available via the
Library Toolbox) via a Library API call...]
- search for a book across catalogues and return availability by Library; [an email earlier today from Ed Chamberlain suggests an API call that is pretty close to this is currently under testing...];
- see a personalised results list showing where *I* (me, not just anyone, me, a member of certain libraries and in a particular year of my studies) can:
- - access those works
now, in a reference context; [discussing with Huw, now is also sensitive to time of day and whether a Library is currently open or not....]
- - access those works for reference now-ish (or at a bookable time) via a stack request (see also
Stack Request Delivery Slots service idea )
- - borrow those works (given the libraries I currently have access to) immediately (or via a stack request)
- - recall a currently on loan item so that i can borrow it (given the libraries i currently have access to)
A map display showing the location of works, maybe using colour coded markers on the map to denote "available now to you for reference", "available to you now for loan", "available for loan if you join this library (which you can)" etc, would bring in both elements of time and place to the display, both key features of a practical mobile app.
This sort of app would also act as driver for other services, and demonstrate an authentic way of how they might be combined together:
- what libraries am I currently registered with? [as mentioned above, a service for this already exists]
- search over an arbitrary set of libraries (not just universal, collegesA-F or whatever) [apparently a service that might fulfil this is currently under testing]; and hence
- search over libraries that I am:
- - allowed to use for reference;
- - registered with;
- - can register with;
[As far as I know, there currently is no way of filtering a set of Voyager results through a personal profile filter to only display books I can currently access. But this is just a case of filtering, if you know: which Libraries I can access, what time it is, and what time the Libraries are open. The Library opening time data is available after a fashion, but not in a structured form. A 1-2 day tidying up job could fix that...]
- Voyager results on a map (showing libraries where holdings are held); [as Huw pointed out once again, some library records point to a map display that locates a library a book is held in (eg
this example for a particular book identified via the URI arguments. Looking at the data from the Library details webservice, not all Libraries have lat/long data associated with them, though they do have postcode data. I posted a Google MyMap that I had hoped to use to start collecting accurate-ish GPS data but that's not something I'v got round to yet,...
sigh... (see
By Way of Introductionfor a link to the map). One thing that would make building an app easier is to provide canned GPS data for all libraries based on postcode data to begin with, maybe with a flag that says it's postcode derived or verified as accurate? ]
If the app was architected as a potentially generic app, other time and place services that might be integrated include:
- my current lecture list CalMap (a map with calendar settings to show eg today's lectures, their times and locations);
- raven wifi access points i can use;
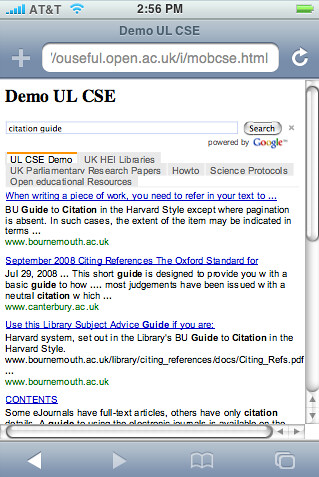
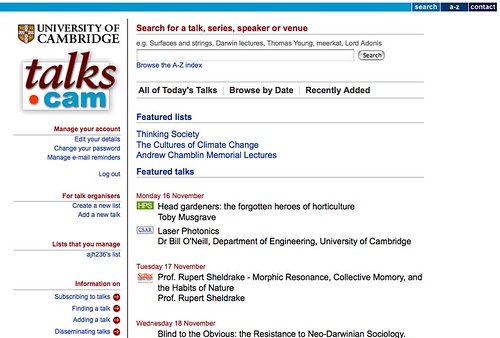
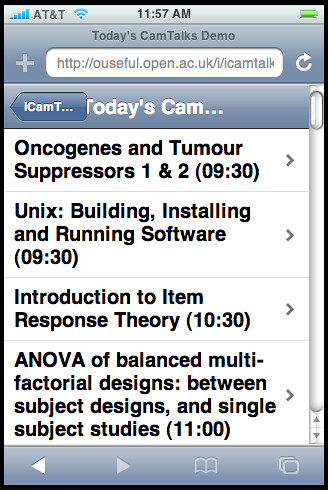
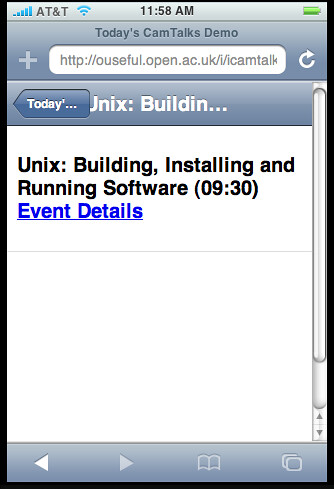
- Cambridge talks calendar-map (I've already done a
mobile listings demo, though it doesn't (yet!;-) include maps... )
- More general local listings etc
We could also push "adverts" to the front page of the app, eg suggesting Library training sessions that might be relevant to a recognised user.
As to what it might look like, I started some doodles...
A simplistic front page:
A map of libraries I'm a member of (well, not
me obviously ;-), pulling data from the service that feeds the Facebook app:
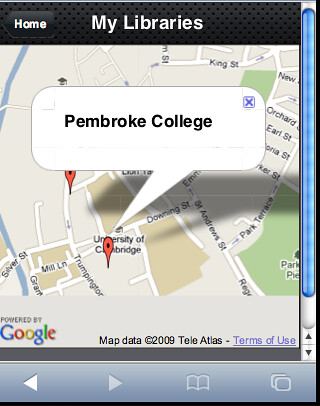
The info bubble could display the books I currently have on loan from that library, perhaps, or address info, etc etc.
That same data as a list:
Each of these items links to a page containing data from the Library info web service - address information, opening times, a link to the Library's home page etc, but either Yahoo Pipes has gone, or the Library's running a batch job or something, but the app has stopped working
again and I'm sick to death of it wimping out on me for tonight, so there'll be no more screenshots tonight...!

(Seems I managed to find a cached copy...)
To make life easier, the app either needs to pull in the XML direct from the (same) browser, and parse it on the app, call on a JSON feed from the originating webservices (rather than go via a pipe) or pull in an HTML page via XHR that is generated on the server from the user's details. Note that the pipework I currently use annotates the list of libraries "I" have access to with the additional Library details from the library info service. If that info directly annotated the record of each Library I'm a member of, it would reduce the amount of pipework required.
PS I considered not posting this in case the local feeling was that a fully complete and working mobile app should be launched as if from nowhere; but then it occurred to me that three or four conversations really drove the thinking captured above and helped crystallise out what might be achievable given current service availability. If nothing else, I'd like for my time on the Arcadia project to demonstrate how free and open conversations can lead to innovation in an institutional setting, and record, albeit informally, one way of how that process might work.
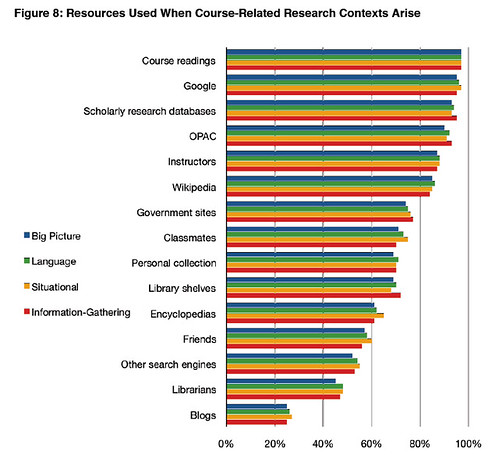
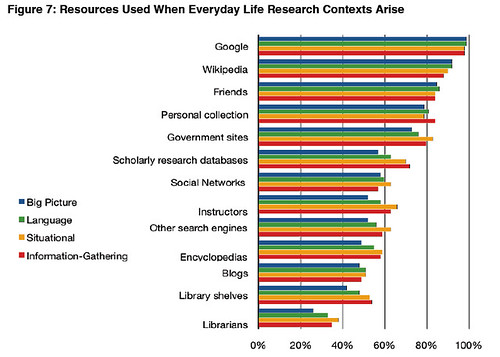
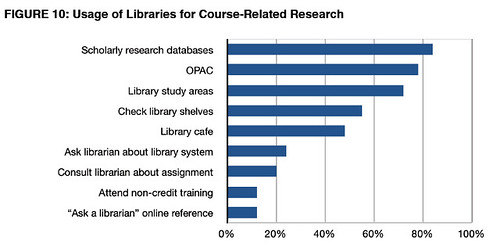
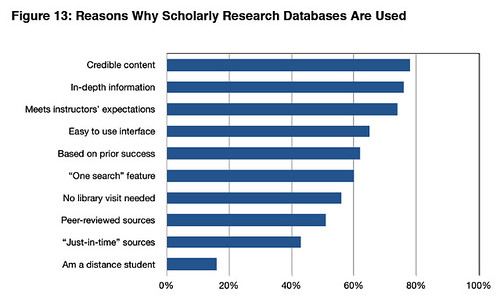
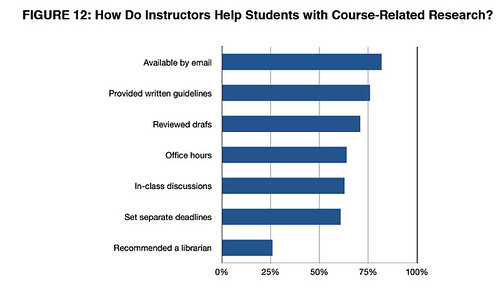
PPS as to whether this sort of app is on the right track, here's a survey result from Keren's
M-Libraries: Information use on the move [pdf] Arcadia report:
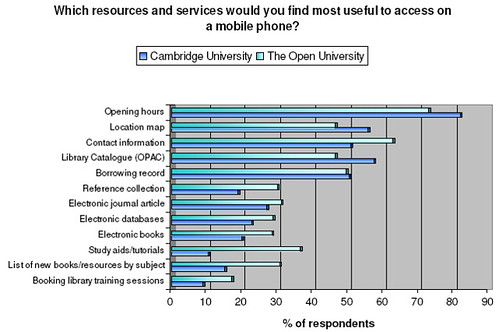
:-)