This relationship between books and courses is one that can be explored, in proof of concept prototype form at least, using data from the JISC MOSAIC programme.
Over the summer, this programme supported a developer competition to encourage developers to "produce a browser based application that makes use of some or all of the MOSAIC library activity data".
The data represented several years' worth of anonymised records relating to books borrowed from an academic library, with book loans linked to course affiliations of the borrowers, as well as their year of study.
Although the data was initially made available as a large XML file, Dave Pattern (@daveyp) from the University of Huddersfield Library rapidly produced a simple web based API to the database (MOSAIC Competition Data API) which opened up the possibility for developers and tinkerers without database experience to participate in the competition.
In all, six entries were submitted to the competition, (comptition results), covering the following areas:
Improving Resource Discovery
- Navigate the ‘Book Galaxy’ through links based on borrowing habits (link: Book Galaxy):
[image to come - I couldn't get the Java applet to work]
- "find books that have been borrowed from your institution's library by students on a particular course, add them to a reading list and share it with others" (link: iLib):
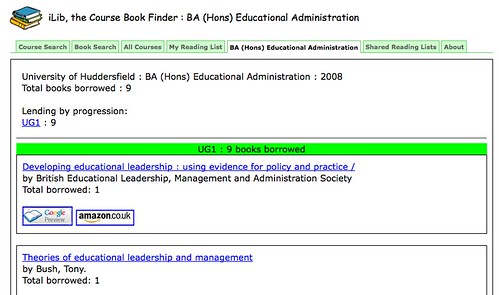
iLib glue: e.g. http://www.codebrane.com/ilib/book_search/?book_searchtext=games, http://www.codebrane.com/ilib/course_search/?course_searchtext=games
Supporting learning choices
- Supporting course choice - augmenting the UCAS course catalogue with books and courses related to a course by virtue of books borrowed commonly across courses(link) [DISCLAIMER: this was my entry; blog post about this app]:
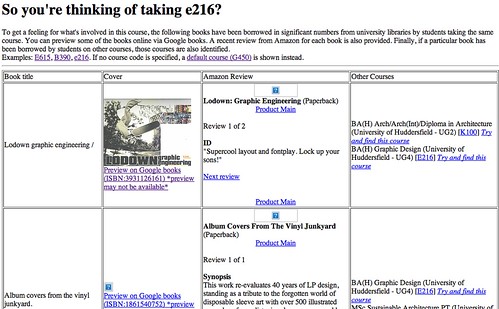
Course selection glue: e.g. http://ouseful.open.ac.uk/mosaic.php?cc=e216, and the various bits of Yahoo pipework associated with the app (listed on the project page)
- Course suggestions based on books you’ve read or that are itemised in a reading list (link: Read to Learn):

Supporting decision making
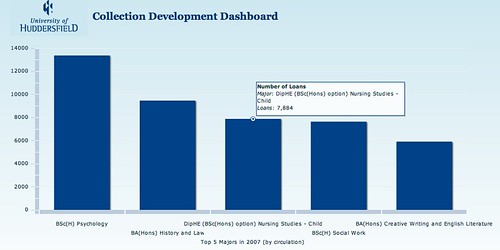
- Assess circulation relating to departments and courses (link: Collection Development Dashboard):
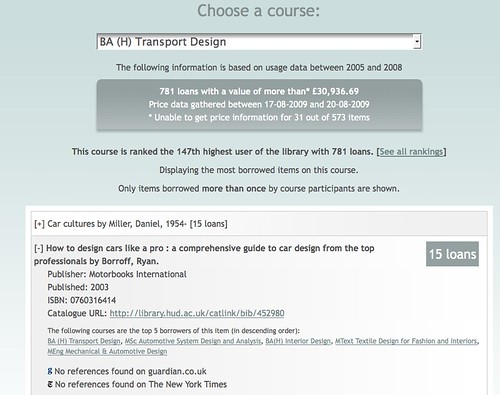
- Value the loans per courses as a collection performance indicator (link):
Aggregated Data
A couple of the apps display reports that crunch aggregated stats from the data in potentially useful ways (e.g. the collection reporting tool and the loan book value tool), although I'm not sure about the extent to which Library systems support bulk reporting already (library systems vendors all seem determined to keep their documentation behind password protected, license holder access only barricades for some reason that I just can't fathom?
The Read to Learn app looks like it combines lookups from several ISBNs to rank suggested courses, which to my mind is more interesting (in a playful, if not useful, sense) than simply totalling figures within a particular set. E.g. I assume that the suggested course rankings will be different for each different set of books you upload and are calculated uniquely for each different set of books? (If I've misinterpreted this, I'm sure Owen will let me know ;-)
"Linked Data" opportunities
On thing that particularly appealed to me about this data was the ability to recommend one thing based on another. In my own application, this took the form of finding courses on which books had been borrowed that were also borrowed on a course that a student browsing a course list on the UCAS website might be considering taking.
At first, I though iLib did something comparably indirect - e.g. using a search term to find a set of books and then using that list of books to identify a set of related courses, or searching for coursenames that contain a particular search term and then reporting back with the books associated with those courses; but I think the course search and book search are actually just literal searches? (i.e. the book search searches for books directly, and the course search searches for course titles containing the search term directly).
I'm not sure what Book Galaxy does from playing with it - I still can't get it to work :-( From the description: "Clicking on a book will show a web of related books for the selected book at the centre, with courses that use the book listed around the outside." So this presumably looks up books related to courses related to a particular book (nice:-). "Clicking on a course will show all the books that are used by that course." But not the courses related to that course by virtue of common books, which would be the corollary of the books related to books approach? (So e.g. my app used a courses to courses mapping.)
Just looking at first and second order relationships, we can get:
- course to books (starting with Course A):
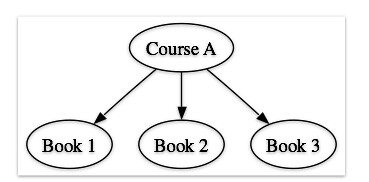
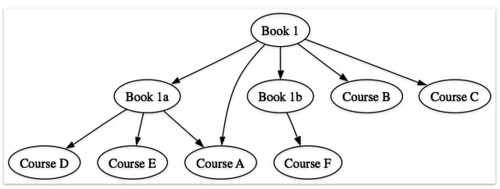
- book to courses (starting with Book 1):
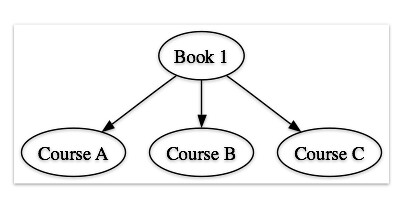
- course to courses (starting with Course A):
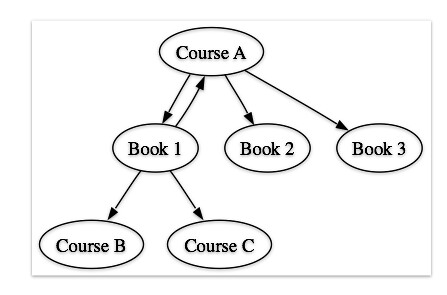
- book to books (starting with Book 1):
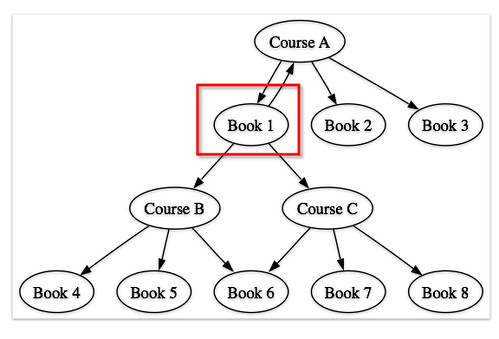
Note that if we take xISBNs into account (and the MOSAIC API supports xISBN lookups), we get a potentially richer map, e.g. when mapping from a book to courses. So for example a book has alternative ISBNs for its diffrent editions, we might get something like:
Anyway, it was interesting to see how different people addressed the competition, although there's not as much glue as I was hoping for (that is, apps with RESTful URIs that can take course codes, ISBNs or free text search terms, and maybe produce RSS, JSON, XML or easily scrapable outputs that don't simply replicate calls to Dave's API).
And as far as the data goes, I think MOSAIC is still accepting data for to add to the mix, and scripts are available (I think?) that can generate a data dump in the required format from a variety of library systems (including Voyager... So how about it, Cambridge?;-)
For more techie details, see the MOSAIC wiki
PS if any of the other competition entry developers have blogged about their apps, I'd love to be able to link to the corresponding posts :-)


No comments:
Post a Comment