BooksServer is a new service from the Internet Archive that aims to provide:
a growing open architecture for vending and lending digital books over the Internet. Built on open catalog and open book formats, the BookServer model allows a wide network of publishers, booksellers, libraries, and even authors to make their catalogs of books available directly to readers through their laptops, phones, netbooks, or dedicated reading devices. BookServer facilitates pay transactions, borrowing books from libraries, and downloading free, publicly accessible books.
The original announcement goes on:
We will demonstrate a live system where:
- Publishers and booksellers are selling digital books on their own terms,
- Libraries loaning digital out-of-print books to their patrons,
- Readers finding and reading the books they love on
- Reading devices of their choice.
Reading devices of their choice. Hmmm.... interesting...
So what does it look like?
Wot no advanced search? Just a minimal web search engine like interface?;-)
How do we do on the results front, then?
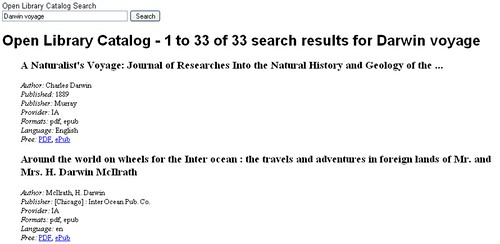
And the search URI for that? http://www.archive.org/bookserver/catalog/search?q=Darwin+voyage, plain, simple and one might even say web conventional.
Now I know there are plenty of folk who would argue that for research purposes there is arguably a dearth of metadata that allows a competent researcher to make a qualified decision about the quality of any of those search results, but there is some bibliographic information there, and more importantly for the user there are links to a couple of differently formatted versions of each book (PDF and ePub in the above examples). (I'd quite like to see a daily feed there too ;-)
The simple style sheet also looks to me as if it would be readable on a mobile device (assuming they don't switch in another stylesheet if a mobile browser/platfrom is detected).
So why's this like URIPlay? For those of you who have never heard of URIPlay (which I'm guessing is probably most readers of this blog?), it's "a name service for media content, giving each file a URI and a simple description. Think of it as DNS for media."
DNS? Domain Name System (service, server) - the hierarchical naming system that defines the web and whose addresses can be resolved in from human readable URIs (www.cam.ac.uk) to the IP (internet protocol) addresses that identify where each server can actually be found on the internet.
The promise of URIPlay is that a user should be able to call the URI for a media resource from a particular device/browser/locale, and URIPlay will resolve that to an instance of the resource that can be played in that particular context. So for example, if I am on a mobile device, I might want the resource delivered in a different format from when I am using a desktop device. When I am in one locale, I might want one version of the resource (a BBC video from iPlayer if I'm in the UK, for example), when I'm in another country from a different provider (potentially a commercial service), and so on.
So far, so straightforward content negotiation. But as I understand it, URIPlay proposes a further step by passing the URIPlay resolver the URI of a media resource, and the resolver will then look at the metadata associated with that resource in order to locate an appropriate instance of the resource that can then be delivered back to the client.
Whilst the URIPlay API spec appears to be focussed on media resources such as audio or video files, when I saw BookServer's promise that it would deliver content to users on "[r]eading devices of their choice", URIPlay immediately came to mind.
In the world of subscription journals, where DOI resolvers identify a particular copy of a resource that a user might access on grounds of (commercial) permissions, this idea of resolution is nothing new, of course. So for example, in conversation with @ostephens and elsewhere, I've often thought of URIPlay in a similar context (that is, like DOI resolution, but to resource types based on device, rather than commercial provider based on affiliation).
So now the question comes to mind: what would URIPlay for academic content look like?


No comments:
Post a Comment