
The search tool is actually a Google custom search engine, defined over the www.lib.cam.ac.uk domain as well as a couple of other different subdomains, with an exclusion applied to an old part of the website. The results are returned in an embedded frame on the Library website, without adverts...
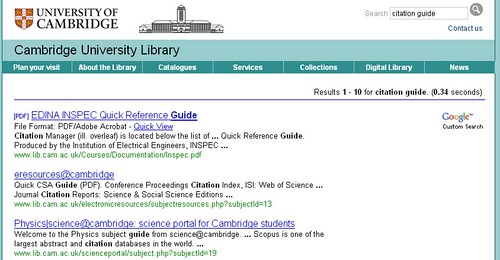
In the post Open Library Training Materials and Custom Search Engines, I showed how I created a Custom search engine that searches over UK HEI websites (a tutorial video on setting up Google CSEs is included in that post).
Adding additional sites, and search refinements that limit searches to a subset of those sites is easily achieved by adding search labels to selected sites.
Embedding a search engine is also trivial - the Google CSE Control Panel provides you with some embed code that can be cut and pasted directly into a document:
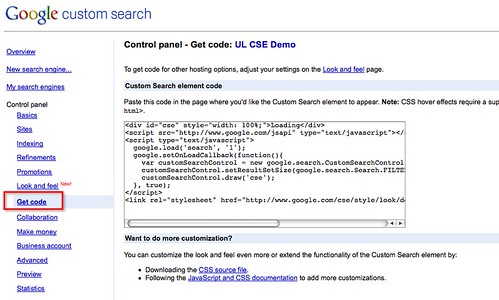
So for example, the above embed code relates to a proof of concept "UK HEI Library Community CSE" that I have pulled together from resources in several other CSEs I've developed over the years - hopefully it should be embedded here:
LOADING....
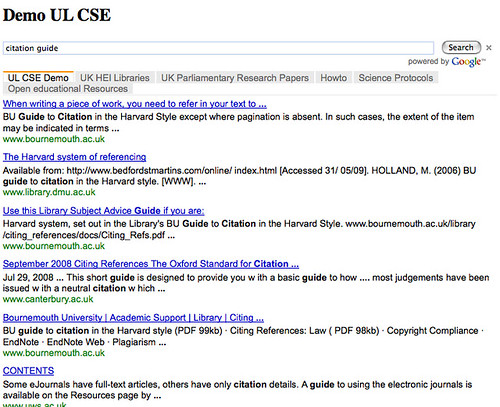
.....LOADING
.....LOADING
Note that because the CSE code is quite clean, just on it's own it presents a reasonable mobile client (though the tabs can be quite hard to click on - so a minor style tweak is required there, I think...?)
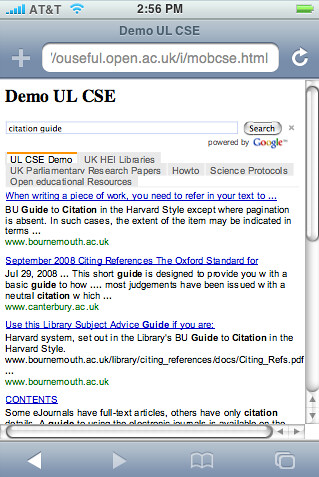
You can try the CSE out here - UK HEI Library Community CSE (QR code)
As it currently stands, the UK HEI Library Community CSE has very little fine tuning - it's just a (sub)domain limited search engine over sites I've picked that may be relevant to the UK HEI community. However, it is possible to tune a Google Custom CSE quite significantly, which I'll start to explore in future posts.


No comments:
Post a Comment