A post on the freeculture blog today (Call for Participation: Join the Open University Campaign!) raises a call to arms "to increase collaboration, sharing, and openness at the level of higher education" and proposes a report card that can be used to assess the level of openness of a Higher Ed institution.
The reporting is proposed around the five tenets of the Wheeler declaration(?): "An open university is one in which:
The research produced is open access;
The course materials are open educational resources;
The university embraces free software and open standards;
The university’s patents are readily licensed for free software, essential medicine, and the public good;
The university’s network reflects the open nature of the Internet,
where “university” includes all parts of the community: students, faculty and administration."
Looking at these aims, I wonder to what extent they might relate to the role of the academic library in a digital world? So for example, is there a role for the Library as the champion of - and gateway to - openness (as described above)? Or should openness initiatives be the remit of other parts of the institution?
One thing I've noticed wandering around the bookshops of Cambridge is that they have started putting up Point-of-Sale marketing displays pushing e-book readers. I'm still not sure whether these will fly or not, though I can see the form factor is more accommodating than reading ebook content on a mobile phone or iPod touch, because I'm not sure what the future of the book is...
For sure, I'm a fan of books (our house is full of them, I buy them regularly, new and old, I borrow them from libraries (note to self: renew overdue library books) and so on), but I'm not convinced that ebooks will necessarily work like books when it comes to buying them. Just like I'm not sure that e-journals are necessarily like print journals when it comes to buying them. Becuase in an academic or technical context at least, books and journals aren't so much as read, as dipped into...
So for example, textbooks and reference manuals aren't necessarily read cover to cover - they tend to be dipped into at a topic, or problem level.
And journals aren't typically read cover to cover, nor are the papers within them necessarily read from start to end. Taking a leaf out of Peter Murray Rust's book, I've been chatting to folk over the last week or so and asking them how they read journal papers - a skim of the abstract, a quick look over the conclusions, and possibly a deep dive into a particular section seems to be as common a way as any.
So with a library purchasing policy based on buying (and lending) whole books, and subscribing to whole journal sets (not just single journals), how does this compare with the way the information contained within these content packages is actually referred to? Not very well, I think?
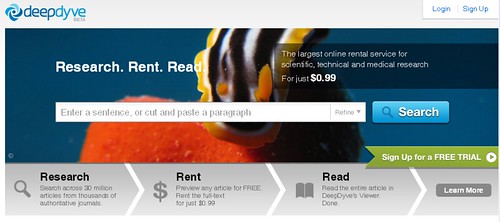
("Article renting" - how does that sound to you?!;-) I haven't looked at the detail of this rental service yet, but with competitive pricing ("For just $0.99 per article, users of this 'pay-as-you-go' plan can rent and read a premium article from one of the many prestigious journals available through DeepDyve. Articles can be read multiple times for up to 24 hours.") I think I can see what they're trying to do... (which is to make the fee bearable for the convenience of accessing the content that is being sold... (that is, the convenience that is being sold...).)
Remembering the various debates around whether services like Google Scholar (and the ill fated Microsoft Live Academic search*) offered a comparable service to subscription databases in terms of the content that was being indexed, I wonder how well the list of publishers/publications that DeepDyve is indexing will stand up?
(* Hmmm.... seems that Microsoft has a research search engine for computer science literature? Microsoft Academic Search)
The TechCrunch post was presumably a lazy response (I hold TechCrunch in very low regard...) to a PR push (and this press release) from DeepDyve following the announcement of Safari Books Online 6.0, which offers subscription access into O'Reilly's online technical books content. (Disclaimer - I buy loads of O'Reilly books... And on the convenience ticket again, I know several members of HEIs who have taken out personal subscriptions to Safari to get round the limited access subscriptions that many institutions have to Safari.)
Looking round the O'Reilly site a bit further, their e-book offerings try to cover the range of likely candidate formats - mobi for the Kindle, PDF for laptops, epub for mobile devices.
And as if to close the circle, there is also an appstore on the O'Reilly domain - O'Reilly Best iPhone Apps:
But what's this - no books category???
So where are we at? When it comes to ebooks, don't think of them as books... to get your creative juices flowing, it may be more rewarding to think of them as apps... ;-)
In The Library's Role in Organising "Course Knowledge", I suggested that one possible role for the library might be in organising the knowledge an institution has, or accretes, around the institution's courses over a period of time.
This knowledge might include things like reading lists, and past exam papers, for example.
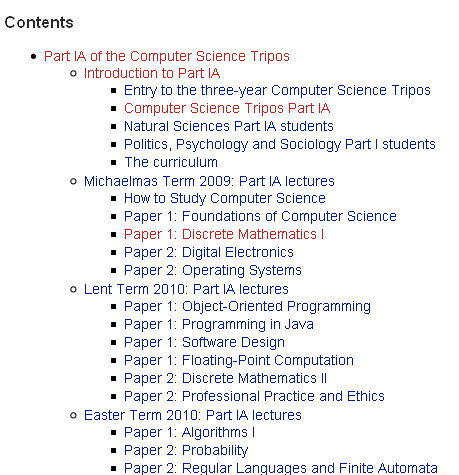
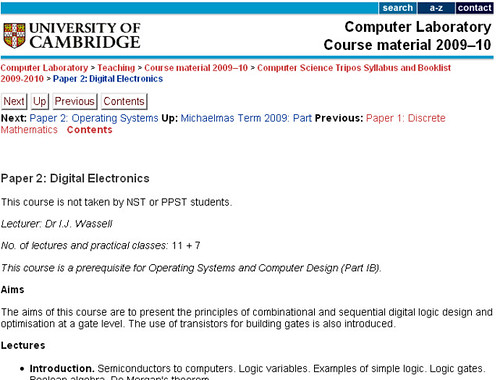
Looking round the .cam.ac.uk website, it strikes me that the Computing Laboratory have already collected a lot of relevant material around their teaching, although not necessarily in a portable format.
So for example, we have a breakdown of syllabus information for each lecture course associated with the Computer Science Tripos for the current academic year:
Each topic has a page associated with it outlining the syllabus, as well as learning objectives and recommended reading:
The format of the URIs is based on a strightforward enumeration: http://www.cl.cam.ac.uk/teaching/0910/CST/node13.html in the above case, for example.
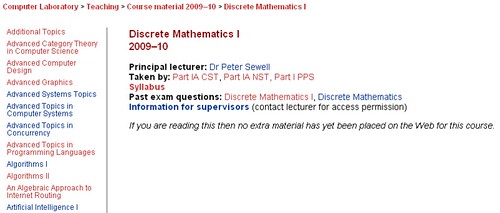
A second area of the site provides a slightly different breakdown of the teaching materials associated with each lecture course:
In many cases, it seems as if the URI is often 'inspired' by the title of the course, e.g. http://www.cl.cam.ac.uk/teaching/0910/DiscMathI/ in the above case.
Included on the course materials page is information that identifies which other programmes (that is, "Subjects" in the CAMSIS parlance) aside from the Computer Science Tripos expect students to take papers/exams in these subjects.
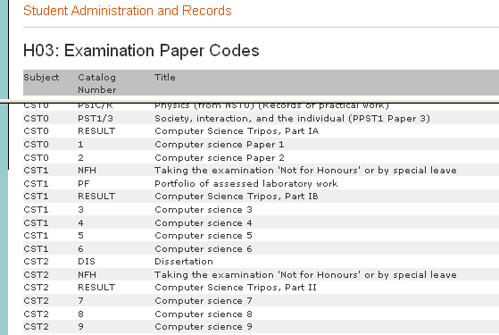
Note that whilst the Subject codes are not explicitly identified on either the syllabus page or the course materials page, they are hinted at in the URI of the syllabus pages, and in the Taken By area of the course materials page. In the above we see CST for example, which is close to the CAMSIS subject code:
Back to the course materials page, and the links to past papers also tend to include a human readable element: http://www.cl.cam.ac.uk/teaching/exams/pastpapers/t-DiscreteMathematicsI.html although it is not necessarily the case that you can directly transform the URI of the past papers page from the course materials page.
Note that there doesn't seem to be a way of identifying the URI of the syllabus page from the course material or past papers page (or vice versa).
The URI of the past papers, whilst readable to an extent, are also not forthcoming in this respect: e.g. http://www.cl.cam.ac.uk/teaching/exams/pastpapers/y2009p1q4.pdf
So what would have been nice? Well what have we got?
- Subject codes (for the Computing Science Tripos, Natural Sciences Tripos, etc), that look something like CST; (there are also UCAS codes, which I suspect must map on to Subject codes, somehow?) - Parts (roman numerals, maybe with an A/B) (which sort of map on to year of study... sort of...); note that subject code + part already have CAMSIS codes defined for them; - Papers (a number), which relate to exams; - (Lecture) courses (titles, numreous incosistent short forms), which map onto a particular paper in the context of a Part and a Subject.
So what would be nice would be: - a unique identifier for each lecture course; - a mapping from a lecture course identifier to past paper, keyed by Subject, part and exam number. Note that (like a DOI) this might be a many to one mapping. So for example, Discrete Mathematics I, which is taken by: Part IA CST, Part IA NST, Part I PPS, might have require four plus one pieces of information in its identifier: e.g. 2009/CST0/1/DM_I for the year, subject and part, paper and course in the Computing Science Tripos, and 2009/CST0/1/DM_1:NST0 for its NatSci variant?
The question number in a particular exam paper might also be handy in cases where each different lecture course has it's own identifiable subsection within a paper.
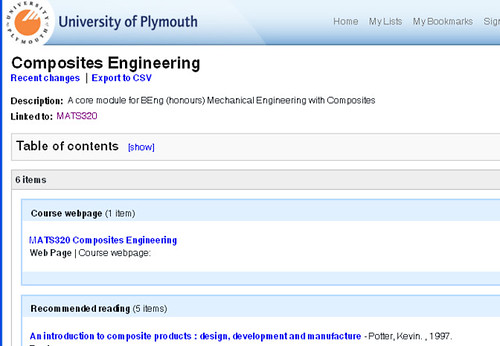
In other institutions, it is likely that the course (module?) will have its own unique identifier. So for example, if we look at the Reading List system at Manchester, we can see how courses there are identified by a unique code within the first year Computing degree:
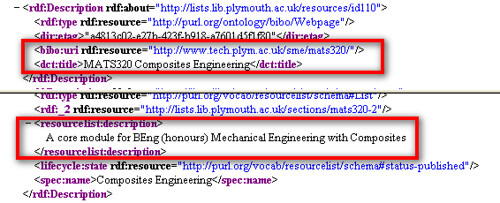
If we tunnel into the Plymouth Reading list system, we find that whilst module codes are identified, there is no link back to the parent degree code:
The RDF version of the page does appear to have an informal (i.e. not by code number) reference back to the 'parent' degree programme, though:
All of which is to say: at the moment there is no obvious/easy way to map from a UCAS code to an internal degree code to a year of study to a particular lecture course to its reading list and/or past papers. And in the Cambridge context, there's no obvious way of going from a URI associated with content relating to any one of those levels to a URI for content relating to any other ;-) (I think!)
The closing question to the panel from my session at ILI2009 a couple of weeks ago related to what skills we thought would be most desirable in the librarian of the future. My response was something along the lines of 'be able to write a good query', the thinking being that if a researcher or undergraduate goes to a subject librarian asking for help, it might be useful if they went away with a good query they could run repeatedly as a saved (persistent, alert raising) search, rather than just leaving with one or two particular references.
So this got me thinking: what are the differences between information skills and information technology skills?
As far as I know, public commenting still doesn't work on this blog, so what skills are you going to have to invoke to be able comment on this post, and what skills am I going to have to use to find those comments...?
As thought provoking as ever, Peter outlines how he believes the current situation with publishers has ensures that Librarians no longer fulfil Ranganathan's five laws.
He also roughly describes how he would like science librarians to work, effectively as information brokers doing all the work scientists currently do by engaging with online communities, publishing in an open fashion and writing new tools.
It seems to me that one of the key, live discussion issues faced by academic libraries at the moment in their 'service to undergraduates' role is the extent to which they integrate with the students' experience of a course (which increasingly means: in the VLE).
In the Open University, the central library's role was originally to support course development and academic research, as well as archiving the university's course materials. Undergraduate access to other academic libraries across the UK was also negotiated by the Library. The rise of e-collections, however, means that the OU Library can now start to provide information access to undergraduate students who access library services remotely.
In Cambridge, too, the central University Library's role, primarily as a research library, but also as a provider of services to College and Department libraries, looks as if the increasing online availability of resources might influence the services it provides directly to undergraduates, in addition to the services it provides through the other libraries.
But to what extent are the libraries looking inside their respective .ac.uk domains (both the public areas and the authenticated ones) and attempting to 'organise learning related course knowledge' - that is, those resources that grow up around a course over the its lifetime.
So for example, we have 'direct' course related outputs, such as course reading lists and past exam papers. Then there are the outputs of data-mining around courses, such as looking at what books students on a particular course borrowed in significant numbers. Where students do their own research on a particular topic, there are resources they have referenced in their work. These may become increasingly discoverable if students start to make use of social bookmarking or reference managing tools, posting course related social bookmarks, for example, as they do their research. For students who subscribe to RSS feeds, OPML feedrolls relating to a particular course might also be available. And as open educational resource initiatives keep testing the waters in terms of releasing course materials under an open license, there are likely to be increasing amounts of course materials (including reading lists, lecture podcasts, or videos etc etc) available relating to any particular course, or at least, course related subject area.
(One OU course I used to mark each year always has a research style question that required students to discover two or three resources to support their answer. I'd bookmark these each year in order to see what sorts of searches students might be doing for the assessment: a lot of the resources seemed to be among the top Google results for an 'obvious' keyword/keyphrase selection suggested by the question.)
So how might a Library go about organising 'course knowledge'?
One approach I have explored in the past are course related search engines. In one early demo, I mined courses on the OU's OpenLearn website for links to external websites, and used these as the basis for a course resources search engine. (I suspect the demo has since rotter: OpenLearn Dynamic Custom Search Engine). In other examples, I would search over the outgoing links from a particular webpage (e.g. 'Search Links On this Page' Revised Bookmarklet - again, this may have rotted...). One course I am currently running uses a Google Custom Search Engine populated by hand with resources linked to from the course materials, providing students with a way of searching over the (public) resources that the course refers to (think of this like a reading list limited search engine).
"Ah yes, all very useful", you may say. "But so what...?" So maybe Google is going to beat the libraries to it again if they don't start thinking in a weblike way. For example, in my feed reader today I learn that Google is now offering Contextual search within Wikipedia:
For Wikipedia pages with a lot of information and links, contextual search lets you limit your search to only those Wikipedia pages that are linked from the current article, focusing the results on the topic of the article. So, in addition to getting all matching Wikipedia articles, you can quickly drill down to contextually relevant results using the Linked Wikipedia Pages tab.
WAKE UP: in most institutions, the course is a context, but how much value is being exploited from that context? To what extent do our 'learning environments' allow linked course resources to be explored as if the learning environment was a research environment?
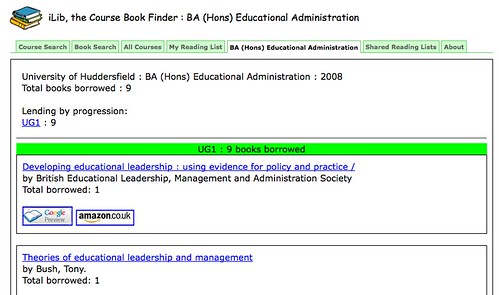
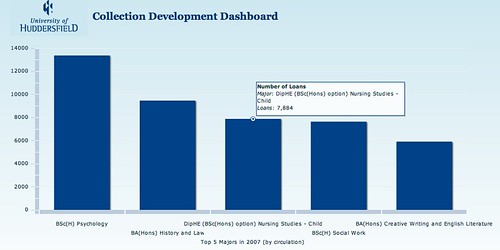
Encouragingly, there are signs of academic Libraries starting to think about the exploitation of course resources. So for example, @daveyp's book recommender based on library loans data looks as if it might be increasing the number of books borrowed at Huddersfield University (ILI2009: Exploiting Usage Data). And at Cambridge, moves appear to be afoot at getting hold of centralised course information data so that it can be used to personalise a variety of library services (more on this in a later post...;-)
Just by the by, clearing out some long ago opened tabs on my web browser ovr the weekend, I came across this post entitled Examopedia, which describes a project at Portsmouth where "questions from a past exam [are posted on a wiki]; students then put their answers to these questions onto the wiki, suggesting alternatives or amendments if an answer has already been posted".
For subjects where short problems are used as one of the drivers for checking understanding and demonstrating techniques, I can see how this might be a really powerful technique. It also got me wondering about the extent to which a service like Stack Overflow (now available as a white label service, Stack Exchange), where users can post questions, receive answers, and share all sorts of karmic goodness, might be used in a similar way? E.g. by allowing past papers to be atomised down to the level of separate questions, posted as such, and then collaboratively addressed by a social learning community?
One question is, to what extent should it be the Library's role to explore the way(s) in which course knowledge can best be organised and exploited...?
One of the joys of chatting to folk under the auspices of the Arcadia programme is that it allows them free reign to talk about all the things they'd like to do, rather than just the things that are on the current day-to-day grind development plan. Today, for example, I attended a meeting that was looking at ways of getting course related data associated with students held in one university administrative database so that it could be used to provide additional context for library services looking to make course related recommendations (reading lists, past exam papers, and so on) to individual students.
This relationship between books and courses is one that can be explored, in proof of concept prototype form at least, using data from the JISC MOSAIC programme.
Over the summer, this programme supported a developer competition to encourage developers to "produce a browser based application that makes use of some or all of the MOSAIC library activity data".
The data represented several years' worth of anonymised records relating to books borrowed from an academic library, with book loans linked to course affiliations of the borrowers, as well as their year of study.
Although the data was initially made available as a large XML file, Dave Pattern (@daveyp) from the University of Huddersfield Library rapidly produced a simple web based API to the database (MOSAIC Competition Data API) which opened up the possibility for developers and tinkerers without database experience to participate in the competition.
In all, six entries were submitted to the competition, (comptition results), covering the following areas:
Improving Resource Discovery
- Navigate the ‘Book Galaxy’ through links based on borrowing habits (link: Book Galaxy):
[image to come - I couldn't get the Java applet to work]
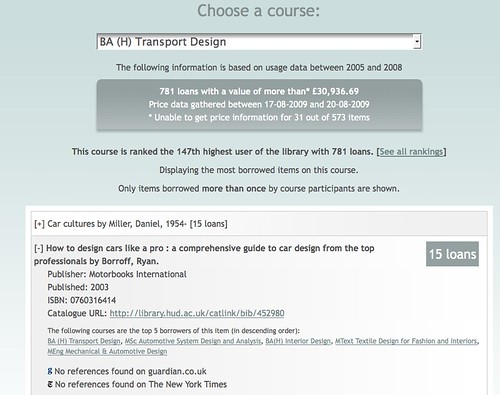
- "find books that have been borrowed from your institution's library by students on a particular course, add them to a reading list and share it with others" (link: iLib):
iLib glue: e.g. http://www.codebrane.com/ilib/book_search/?book_searchtext=games, http://www.codebrane.com/ilib/course_search/?course_searchtext=games
Supporting learning choices
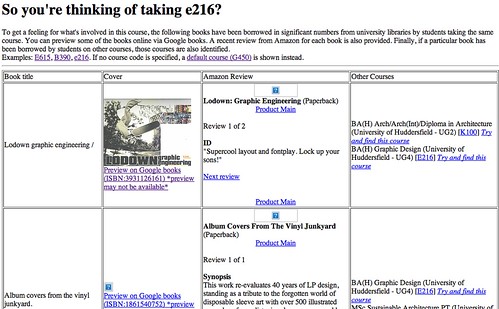
- Supporting course choice - augmenting the UCAS course catalogue with books and courses related to a course by virtue of books borrowed commonly across courses(link) [DISCLAIMER: this was my entry; blog post about this app]:
Course selection glue: e.g. http://ouseful.open.ac.uk/mosaic.php?cc=e216, and the various bits of Yahoo pipework associated with the app (listed on the project page)
- Course suggestions based on books you’ve read or that are itemised in a reading list (link: Read to Learn):
- Value the loans per courses as a collection performance indicator (link):
Aggregated Data A couple of the apps display reports that crunch aggregated stats from the data in potentially useful ways (e.g. the collection reporting tool and the loan book value tool), although I'm not sure about the extent to which Library systems support bulk reporting already (library systems vendors all seem determined to keep their documentation behind password protected, license holder access only barricades for some reason that I just can't fathom?
The Read to Learn app looks like it combines lookups from several ISBNs to rank suggested courses, which to my mind is more interesting (in a playful, if not useful, sense) than simply totalling figures within a particular set. E.g. I assume that the suggested course rankings will be different for each different set of books you upload and are calculated uniquely for each different set of books? (If I've misinterpreted this, I'm sure Owen will let me know ;-)
"Linked Data" opportunities On thing that particularly appealed to me about this data was the ability to recommend one thing based on another. In my own application, this took the form of finding courses on which books had been borrowed that were also borrowed on a course that a student browsing a course list on the UCAS website might be considering taking.
At first, I though iLib did something comparably indirect - e.g. using a search term to find a set of books and then using that list of books to identify a set of related courses, or searching for coursenames that contain a particular search term and then reporting back with the books associated with those courses; but I think the course search and book search are actually just literal searches? (i.e. the book search searches for books directly, and the course search searches for course titles containing the search term directly).
I'm not sure what Book Galaxy does from playing with it - I still can't get it to work :-( From the description: "Clicking on a book will show a web of related books for the selected book at the centre, with courses that use the book listed around the outside." So this presumably looks up books related to courses related to a particular book (nice:-). "Clicking on a course will show all the books that are used by that course." But not the courses related to that course by virtue of common books, which would be the corollary of the books related to books approach? (So e.g. my app used a courses to courses mapping.)
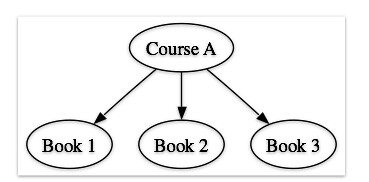
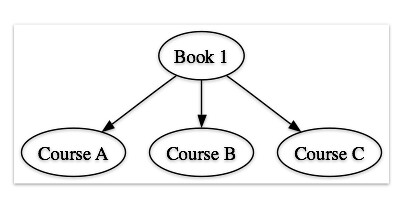
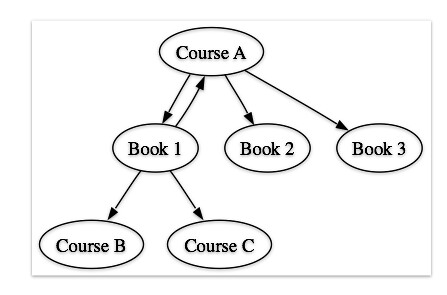
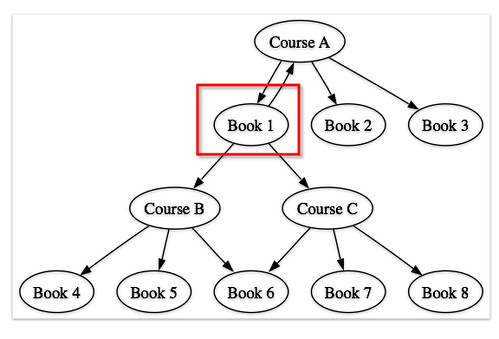
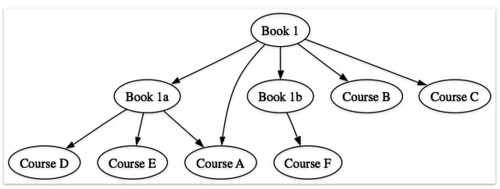
Just looking at first and second order relationships, we can get:
- course to books (starting with Course A):
- book to courses (starting with Book 1):
- course to courses (starting with Course A):
- book to books (starting with Book 1):
Note that if we take xISBNs into account (and the MOSAIC API supports xISBN lookups), we get a potentially richer map, e.g. when mapping from a book to courses. So for example a book has alternative ISBNs for its diffrent editions, we might get something like:
Anyway, it was interesting to see how different people addressed the competition, although there's not as much glue as I was hoping for (that is, apps with RESTful URIs that can take course codes, ISBNs or free text search terms, and maybe produce RSS, JSON, XML or easily scrapable outputs that don't simply replicate calls to Dave's API).
And as far as the data goes, I think MOSAIC is still accepting data for to add to the mix, and scripts are available (I think?) that can generate a data dump in the required format from a variety of library systems (including Voyager... So how about it, Cambridge?;-)
Okay, so what's BookServer, and why's it like URIPlay, whatever that is?
BooksServer is a new service from the Internet Archive that aims to provide:
a growing open architecture for vending and lending digital books over the Internet. Built on open catalog and open book formats, the BookServer model allows a wide network of publishers, booksellers, libraries, and even authors to make their catalogs of books available directly to readers through their laptops, phones, netbooks, or dedicated reading devices. BookServer facilitates pay transactions, borrowing books from libraries, and downloading free, publicly accessible books.
We will demonstrate a live system where: - Publishers and booksellers are selling digital books on their own terms, - Libraries loaning digital out-of-print books to their patrons, - Readers finding and reading the books they love on - Reading devices of their choice.
Reading devices of their choice. Hmmm.... interesting...
Wot no advanced search? Just a minimal web search engine like interface?;-)
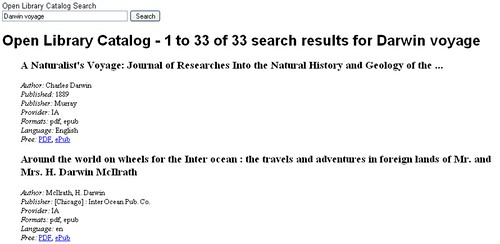
How do we do on the results front, then?
And the search URI for that? http://www.archive.org/bookserver/catalog/search?q=Darwin+voyage, plain, simple and one might even say web conventional.
Now I know there are plenty of folk who would argue that for research purposes there is arguably a dearth of metadata that allows a competent researcher to make a qualified decision about the quality of any of those search results, but there is some bibliographic information there, and more importantly for the user there are links to a couple of differently formatted versions of each book (PDF and ePub in the above examples). (I'd quite like to see a daily feed there too ;-)
The simple style sheet also looks to me as if it would be readable on a mobile device (assuming they don't switch in another stylesheet if a mobile browser/platfrom is detected).
So why's this like URIPlay? For those of you who have never heard of URIPlay (which I'm guessing is probably most readers of this blog?), it's "a name service for media content, giving each file a URI and a simple description. Think of it as DNS for media."
DNS? Domain Name System (service, server) - the hierarchical naming system that defines the web and whose addresses can be resolved in from human readable URIs (www.cam.ac.uk) to the IP (internet protocol) addresses that identify where each server can actually be found on the internet.
The promise of URIPlay is that a user should be able to call the URI for a media resource from a particular device/browser/locale, and URIPlay will resolve that to an instance of the resource that can be played in that particular context. So for example, if I am on a mobile device, I might want the resource delivered in a different format from when I am using a desktop device. When I am in one locale, I might want one version of the resource (a BBC video from iPlayer if I'm in the UK, for example), when I'm in another country from a different provider (potentially a commercial service), and so on.
So far, so straightforward content negotiation. But as I understand it, URIPlay proposes a further step by passing the URIPlay resolver the URI of a media resource, and the resolver will then look at the metadata associated with that resource in order to locate an appropriate instance of the resource that can then be delivered back to the client.
Whilst the URIPlay API spec appears to be focussed on media resources such as audio or video files, when I saw BookServer's promise that it would deliver content to users on "[r]eading devices of their choice", URIPlay immediately came to mind.
In the world of subscription journals, where DOI resolvers identify a particular copy of a resource that a user might access on grounds of (commercial) permissions, this idea of resolution is nothing new, of course. So for example, in conversation with @ostephens and elsewhere, I've often thought of URIPlay in a similar context (that is, like DOI resolution, but to resource types based on device, rather than commercial provider based on affiliation).
So now the question comes to mind: what would URIPlay for academic content look like?
iPhone Apps that might be relevant to researchers:
Evernote Evernote, which started out as a simple note taking tool, is now a solid information manager that can handle everything from voice notes to clippings pulled from the web. The beauty of Evernote is its versatility. You can use it to collect notes from meetings and whiteboards directly to mobile devices, adding voice memos for better clarity. It can make one more efficient, especially with its ability to sync with all the different devices on which I'm running Evernote. Take a note on iPhone/iPodTouch, and it gets automatically synced to home desktop, laptop, netbook, and work PC. Price: Free URL: http://www.evernote.com/
Papers A bit like Mendeley. Bills itself (as Mendeley does) as "iTunes for research literature". Just as iTunes lets you sync your music with your iPod - the Papers app now has a companion app for the iPhone/iPod Touch that allows you to sync your collected journal papers. You can keep copies of all or some of your research papers on your mobile device for quick reading and reference. The built in pdf reader on the Papers app does the job comfortably and can be handled with versatile touch gestures. Papers also features "beaming" where users can send a pdf to another user or sync their library with a desktop wirelessly. Price: $9.99 URL: http://mekentosj.com/papers/iphone/
PubSearch Plus PubSearch Plus gives you the ability to search PubMed from the comfort of your iPhone or iPod Touch, and lets you read and email selected publications. Though the iPhone screen isn't ideal for viewing high resolution images in research papers, it definitely helps when you're looking up a specific piece of information from a particular paper. The app also supports EZProxy so you can connect to journals that are available only through institutional access. Price: $1.99 URL: http://www.deathraypizza.com/deathraypizza/iPhone.html
Academic libraries face specific challenges -- emerging technologies present new opportunities
Academic libraries face specific challenges because of evolving user behaviour. New technologies provide the answers. Addressing the issues faced by academic libraries in a changing world, emtacl10 provides an opportunity to engage with like-minded professionals, and discuss the issues that are specifically relevant to us. emtacl10 — the international conference for cutting-edge technological developments in libraries within higher-education. The future success of academic libraries is dependent on in-depth understandings of the relevance of emerging technologies. Our focus must be on accessibility, interaction, intuitivity, sharing, user-driven content and other web 2.0 challenges. This is a conference for academic library workers and others with a general interest in emerging technologies and electronic information services.
Interesting article in today's NYT about the challenges posed by the coming avalanche of experimental data.
The next generation of computer scientists has to think in terms of what could be described as Internet scale. Facebook, for example, uses more than 1 petabyte of storage space to manage its users’ 40 billion photos. (A petabyte is about 1,000 times as large as a terabyte, and could store about 500 billion pages of text.)
It was not long ago that the notion of one company having anything close to 40 billion photos would have seemed tough to fathom. Google, meanwhile, churns through 20 times that amount of information every single day just running data analysis jobs. In short order, DNA sequencing systems too will generate many petabytes of information a year.
The article makes the rather good point that today's university students, for the most part, will be imprinted on the rather feeble personal computer technology that they use today, and so are not attuned to the kit that will be required to do even routine science in a few years. It cites some of the usual scare stories -- e.g. from astronomy:
The largest public database of such images available today comes from the Sloan Digital Sky Survey, which has about 80 terabytes of data, according to Mr. Connolly. A new system called the Large Synoptic Survey Telescope is set to take more detailed images of larger chunks of the sky and produce about 30 terabytes of data each night. Mr. Connolly’s graduate students have been set to work trying to figure out ways of coping with this much information.
One of the things I've learned about the Cambridge University Library is that you're not necessarily allowed to fetch a book from all the shelves yourself (mainly as a result of the logistics of managing a large collection that arises as a result of being a legal deposit library). Instead, you have to put in a stack request via the online Library catalogue or a paper slip:
Book Fetching Items will be fetched as quickly as possible, but delays are inevitable at certain times of day (especially 12:30–14:15 and 17:15–18:20) and during busy periods. Generally fetching times fluctuate between 30 and 120 minutes, depending on demand. The current estimated fetching time is always displayed both in the room and whilst placing an online Stack Request. Orders submitted after 18:20 (16:00 on Saturdays) will be fetched on the next working day.
Once fetched, books are placed on a stand behind the staff desk area. Books are held for the remainder of the day they are fetched and one full working day thereafter before being returned to the shelves. On the second day books are placed on a shelf along the back of the staff desk area.
If you wish to order more than ten books at one time, please consult staff before placing your order.
(Hmmm - the above guidance is from the Reading Room. Stack Request guidance for the West Room uses completely different text... But presumably the mechanics of making the request are similar, at least as far as the patron is concerned?)
When you make an online request, a request appears on a Voyager Call Slip screen and prints out a request slip, the Call Slip screen shows all currently pending requests and the user is given an estimate of the time to delivery.
A fetcher collects any currently outstanding slips and goes into the stacks to collect the required book(s). A tear-off is placed on the appropriate shelf where each book is taken from (some are borrowable, many aren't, and must remain in the Library confines), returns to the desk and scans the request slip. This completes the transaction, clears it from the screen, and sends an email to the patron letting them know the book is ready for collection. It's then placed on the public recent deliveries shelf for collection, and will remain there for a day if uncollected. Books that are not borrowable may be reserved inside the library for up to three days by leaving them on a desk with a reserve slip in them.
The collection takes anything from 15 mins to a couple of hours on a busy day (I think) with expected turnaround time of 45 minutes.
A paper based reservation system is also available.
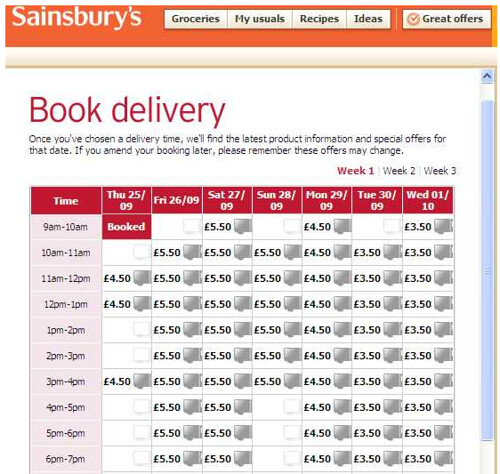
So what if I'm doing some desk research and want to request several books to browse through in a single visit, or over a couple of days?
Or what if I'm at my desk in one of the departments on the other side of Cambridge, but fancy a walk over to the main library building for an afternoon of scholarly activity? Wouldn't it be convenient if I could book a delivery slot for the books I want to put a stack request in for?
On a quiet day, fulfilling requests in a timely way doesn't seem to be an issue, but at busy periods, it may be that a bit of scheduling might help?
This could also help the fetchers schedule what books to collect when. They don't necessarily have to go and fetch a book slotted for this afternoon just yet; instead, they can maybe pick it up in an opportunistic way when servicing another requirement later in the day, or dlay fulfilling a particular request if a rush is on (or if several requests need fulfilling from far flung stacks). Indeed, the ability to request a delivery slot opens up the possibility for all sorts of complicated collection scheduling algorithms - a bit of a knapsack problem with a twist of timetabling and a dose of the traveling salesman, perhaps?!;-)
So what sort of hackery might be fun to try around this process?:-)
As far as scheduling goes, it might convenient to allow a patron to specify the soonest they want the book(s) to be available, with as soon as possible set to be the default. Specifying a later delivery slot would place the request in a queue that would hold the request until a quiet period, or release it when a more timely request for a similarly located item was made (if a fetcher is going to floor N, stack M, where a queued requested item is also located, they might as well get both at the same time).
Of course, the system appears to be working pretty well at the moment, but I couldn't help but notice that the library is building another extension, and is continually in receipt of new books, so I'm guessing the travel time spent collecting new books is only likely to increase (I don't think there's an option to locate books closer to the reading rooms depending on how often a book is requested, so presumably newer books are located further away as the library grows out?)
With interest in building library relevant mobile applications, too, it makes sense to start thinking about time and location features as part of the mobile UI, as well as looking elsewhere for inspiration.
So that's the first possibility - accommodating a delivery slot request, and then potentially building some intelligence into the scheduling of those requests.
The second possibility, and the first thing that came to mind when I saw the collection completion step that fired a 'your item is ready for collection' email to the requester, was a hook to fire off an SMS text message, IM message or tweet instead (or as well). Yes, users can receive email on their phones, but how many have their phone set up to receive mail from their @cam.ac.uk account? How much more convenient would it be to be able to receive a delivery notification via a mobile or always on/alerting messaging client you do use? I'm not sure if the Voyager Call Slip system can be used to raise events that your own code can respond to (all the Voyager documentation I've almost found appears to be locked down in password demanding websites, which isn't very friendly and puts me off old school commercial OPAC vendors even more;-), but if so, this would be quite a nice hack to try out, although it does require additional user information, such as mobile phone number, IM or Twitter ID, etc.
Th third thing that comes to mind may only be an issue because I put a paper slip stack request for a particular book in, rather than an electronic request, and potentially also because the book I requested was borrowable, but I haven't loaned it out - the Library catalogue thinks the book I requested, and that is currently reserved on a table, is available:
That is, the Library catalogue (in this case at least) does not reflect the state of the book - off shelf, somewhere in the Library... Maybe if I'd booked the book out electronically, it would have had its state changed when the slip was scanned to complete the request? Or maybe amidst my question asking, a step was missed out? But whatever the case, there appear to be several opportunities for a book to appear as if it were available as far as the catalogue is concerned, yet for it not to be available in practical terms. (If a stack request can't be fulfilled because a book is off-shelf, or for another reason, that information is sent back to the patron in the request completion email. But the fetcher has potentially had a wasted trip.)
So the third thing I was left wondering, and something that I woke up puzzling about this morning, was how each book's status was represented in state machine terms? And what demands on the data model/required state information might be affected if RFID tags start to come in and make the Library self-aware with respect to where the books are in it?
Thanks to Lucas in the Reading Room for walking me through the stack request process. Comments from @ostephens:
-- The LMS documentation issue is a frustration for me as well - I just cannot understand what the suppliers think they are really protecting here. Although obviously I can see that there is the potential of others copying their solutions to problems, I'm not sure the problems are really so difficult you are protecting any really valuable IP here :( ModerateFlag Like Reply
-- Answering the question about whether a book is on the shelf is often not as easy as you'd hope. Library systems generally track a few statuses of a book:
On loan On a 'holds' shelf (i.e. being held by the library for a specific user) In transit (i.e. being moved from one library site to another) On shelf Missing/Lost
and that is basically it. Some systems have other types of functionality to handle some slightly different scenarios but generally these 5 are the basics I think.
Two other statuses that exist but systems aren't able to record are 'being used in the library', and 'being reshelved' (and this can be either after return from a loan, or after in library use)
I have worked with a system that implements a time delay between return of an item and it appearing as 'on shelf' in the system (don't know how many systems support this, but it makes some sense to the alternative of scanning it when you actually place it back on the shelf). However, this doesn't tackle the 'in library use' or subsequent reshelving time (which could be a day or more, as books left on desks may not be cleared immediately, especially if there is some type of 'note' system to reserve items on a desk)
On a quick visit to the Lee Library in Wolfson College, my all too brief conversation with librarian Anna Jones turned up a niggle with the discharge of books from the library.
As a self-service library, users must: - scan the barcode in each book they want to borrow; - wipe the book to demagnetise the magnetic strip inside it; (I think there was a period of charging the desensitiser too?)
On leaving the library (which also requires a swipe of the user's College Card) the book passes through a detector. If a book has not been desenstised, an alarm rings and a video recording made of the miscreant.
One of the problems with the system seems to be that having apparently checked out a book as far as the catalogue system is concerned, the user may not necessarily properly demagnetise the strip inside the book, which means that a user may inadvertently set off an alarm.
So here's where I call on the assistance of any Arduino touting hardware hackers out there. What I want is simple sensor based app that I can wave a book over and it will give me a green light for desensitised, and a red light for still sensitive. Having physically wiped a book, a user should be able to just wave it over the sensor and check they've got a green light, rather than going to the exit barrier and checking by way of seeing whether the alarm is set off or not.
I don't really know how the magnetic stripes work (nor whether they are 3M Tattle Tapes* or an alternative system), though it is a magnetism based system. But surely a simple short range detector can't be that hard to hack together? (I couldn't find anything on Make:-( Hmmm, I wonder, do the vendors sell hand held detectors anyway, that a user could use just to check they've wiped a book properly?
* I'd often wondered who sold the physical detectors that are on the entrances of pretty much every library and major chain High Street retailer, or the range of systems available, so this provided another piece of the 'how the world works' jigsaw puzzle for me:-)
PS There is another issue with the false negative detection of un-desensitised books leaving the library - apparently the detection bars are too far apart and books can slip through the middle... Which means if they are brought back to the library they may set of the alarm because they were falsely allowed out...
With an RFID system, each book has a unique RFID identifier which can be used to check the integrity of the state of the catalogue with the physical state of the library - which is not something that the current security system respects. (That is, books that enter/leave the library do so anonymously.) RFID tagged books also make intelligent/smart sleves a possibility (e.g. smartBlade. I wonder if they do tabletop RFID readers too, so you can locate books that have been left on tables? Or maybe smart miscellaneous returns shelves would be an effective halfway house?).
This reconciliation of the physical state of the library and the catalogue state isn't something that's really occurred to me before, although it does make me think of Pachube for some reason...
Hmmm...
PPS comments still appear not to be working on this site, but they are appearing on Google SideWiki... e.g. this comment from Owen Stephens makes a couple of valid points about the potential for illegitmate user access to a security detector:
Some (not all) library staff versions of the demagnetisers do have a light to show the status of the strip.
However, I can see a problem with giving this functionality to the users - which is that it would be possible to try books that you hadn't issued to yourself on the off chance they hadn't been re-sensitised properly, and therefore identify 'stealable' books. Also libraries have cases of people defacing books to try to get rid of the security mechanisms - but they aren't always successful. Such a system would give the chance to check this.
... so before I'd be happy to look at a user facing 'check security status' option, I'd want an assessment of how this might affect security.
I suspect if you want to steal a book from any library, it's not that hard. The Library in question is open 24 hours a day, accwess controlled on entry and exit using a personal ID card, and is completely self-service. The thought above was based purely on trying to minimise embarrassment and finding ways of not putting users off borrowing books.
TEST: Sidewiki comments
[UPDATE: not working 1/11/09 - "We are currently adding documentation and robust support for retrieving all entries for a given page through the API (currently, it only returns entries above a certain quality threshold,so that set of entries may change over time)." [ http://groups.google.com/group/google-sidewiki-api/browse_thread/thread/40f25b2c6fc1f4fd%23 via @fawcettbj ]]
New research conducted by Ipsos MORI shows how academic library and IT services are budgeting for today’s economic conditions, but are in need of help to scenario plan for the long term impact of the recession.
‘The impact of the economic recession on university library and IT services’ report, commissioned by JISC, SCONUL and UCISA, contains the findings of 40 interviews carried out in 36 universities across the UK.
The research shows that library and IT services are adept at managing their budgets year on year, but acknowledges that there is a need to develop creative solutions to be able to offer the current 24 hour access to resources students, academics and researchers currently expect.
It also warns that the impact of any cuts is likely to have wide implications on institutions’ delivery of their overall strategic aims, such as enhancing the student experience.
“Identifying and addressing the current impacts of the recession is only part of the process. The greater challenges lie further ahead, five or more years from now, so more work is needed to scenario plan for the future if the knock-on effects are to be fully understood and mitigated to any extent.” said Charles Hutchings, market research manager at JISC.
JISC has invested and is continuing to invest a number of areas that will help to address these issues, for example:
JISC Collections continues to play a key role in supporting institutions to achieve the most cost-effective and consistent deals possible. Alongside this, Open Access models should help to mitigate the increased costs in journal subscriptions
Since 2006, JISC has been helping institutions to develop physical spaces that anticipate the pervasive use of technology in education and research
The JISC-led Strategic Content Alliance has produced a number of guides, toolkits and case studies on how to identify the way in which services and resources are used. As well as valued by appropriate audiences, to, among other things, inform long-term planning
The new Green ICT programme is helping universities and colleges estimate the carbon footprint left by their computers, to help target areas for energy saving
Sometimes, a fresh pair of eyes can make all the difference... And sometimes, the naive question is quite revealing...
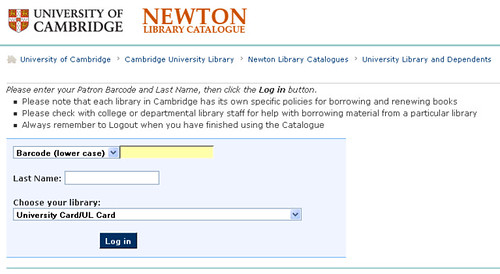
Here's a case in point - I want to make my first Stack Request via Newton...
(Ok, I'll pause there for a minute: stack request? Newton? It's Week 1 of a new academic year and not all of the current intake will speak the lingo yet...)
Here's what I see:
Note the guidance: Please enter your Patron Barcode and Last Name, then click the Log in button.
I presumably need to enter the Barcode (lower case) from my University Card/UL Card?*
Here's my (slightly modified ;-) Library Card:
Hmmmm... Barcode (lower case)? Errr....? So that's abcde? Or veg_7.2? (Why can't a form validator handle case mapping, anyway?!;-)
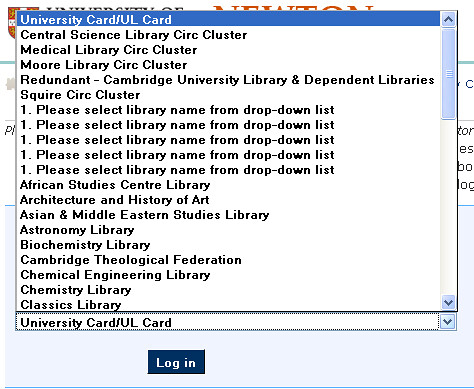
# Select, if required, University Card/UL Card from the drop-down list in the Home Library box (only necessary when using the Universal Catalogue) # Enter your barcode in the Barcode box (the five-character code on your Library/University card)
Ahh... Barcode (lower case) = (the five-character code on your Library/University card)
Which will be ABCDE, presumably? Only in lower case: abcde... (Erm, err, just as an aside: Library/University card...? So - err, do I have a University card? Or is that the same as the Library card? That is, is the Library card my University card?)
Anyway - the moral of the tale is...? Maybe the University Library Card is the most important card I carry, and maybe it's obvious which set of characters is the barcode (err.... the barcode is the barcode, right? For no good reason, I'm not convinced that most people realise that barcodes actually decode to alphanumeric characters?)
Anyway, IMHO, it's not... Obvious, that is... Obvious, that is, which set of characters are the Patron Barcode, or Barcode (lower case).
A lot of interface design issues are problematic the first time round, and they can be quite hard to spot when you're familiar with a system even after only a couple of days use. But for the first time or occasional user, it's the little "isn't it obvious" assumptions that can make systems unfriendly to use: "BUT WHY SHOULD I KNOW THAT?!"
(By the way: hands up if you speak barcode/know how to decode one... Also: today is the 57th Anniversary of the invrention of the barcode. And yet again, Google gets a bucketload of free advertsing from all and sundry: Google doodle: 57th anniversary of invention of the bar code)
* Seems like there's an error in whatever is powering the 'Choose Your Library' selection box...
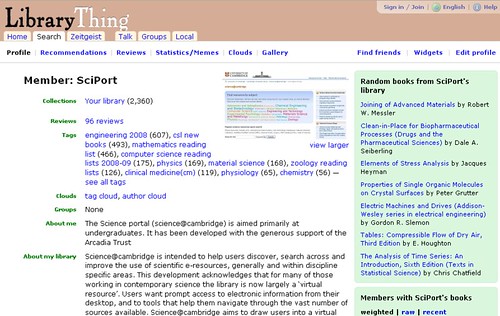
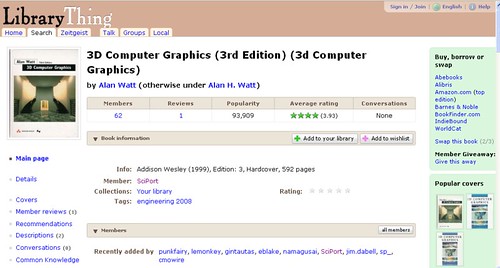
That is, a feed from - and link to - a Cambridge Library new science books account on LibraryThing - SciPort:
I'm not sure how the Library Thing account is kept up-to-date? Does LibraryThing support synching somehow? As science@cambridge was set up under the aegis of the Arcadia project (I think?), somebody on the team must know?! ;-)
I have to admit, though - this willingness to engage with new ideas has really impressed me...:-)
[Note - the rest of this post is concerned with the visual - the surface appearance of the library catalogue front end, not is search tools, indexing and metadata capabilities, etc. If OPAC front ends were designed with web standards in mind, a lot of the shiny stuff could be added with a bit of re-skinning... But in the main, their HTML is horrible... Also remember that I come from the rapid prototyping camp - could we get something up and running in a day or two?]
So what does LibraryThing offer? Firstly, you can add books to your account, in order to maintain a collection of records about books you own (or presumably, have read). Secondly, you can search through user's collection:
The results are also available in a cover based view:
I wonder how hard it would be to add a coverflow view - e.g. as 'pure coverflow':
or as a more traditional carousel:
(Certainly on the iPod Touch, I find the flickable cover flow interaction lets me skim through album covers until I find the one I want to be very effective, efficient, and maybe even more pleasant than a click based interaction?)
The records for each book are centrally held, which makes sense, and user stats are aggregated across the public users of the LibraryThing site:
The "Buy, borrow or swap" column on the right hand side is interesting... What if an institution hosted its own version of LibraryThing, gave all the patrons an account (and also everyphysical library) and books were tracked that way? What if Libraries that had a book available for loan advertised that book via the Member Giveaway, and a patron that had borrowed a book could also loan it on via the Member Giveaway facility, an approach not unlike the Bookcrossing idea, I suppose?
An alternative social front end to the OPAC can be put together using Scriblio/WP-OPAC. Joss WInn at Lincoln is soliciting thoughts on a hosted version of Wordpress/Scriblio that Libraries could use to set up their own Wordpress catalogue frontends without too much grief or technical expertise: Open Education: Talis Incubator Proposal
Imagine that JISC, Talis or Eduserv offered such a platform to UK university libraries. It could be a service, not unlike wordpress.com, where authorised institutions, could self-register for a site and easily import their OPAC, apply a theme, tweak some CSS, choose from a few useful plugins, and within less than a day or two, have a branded, cutting-edge search and browse interface to their OPAC, running under their own domain.
Again, Scriblio offers most of what you'd expect from a visual, social front end to a catalogue - covered illustrated results:
Location information, some desciptive text and category labels:
A bit of metadata, and some related works:
(I think it's important not to underestimate related works - part of the joy of a physical library is the role of serendipity in finding books that are related to the one one you thought you were looking for, and that might actually suit your needs better...)
And that's maybe a point worth finishing on... As well as social and visual features, these informal book catalogue solutions expose simple machine readable interfaces that third parties can build on. The catalogue layer is a representation surface that supports search and discovery not just on the Library website, but also potentially on third party sites, and using third party skins.
If you want to keep control of you data, whilst maximising its effective web exposure, you have to share it. Otherwise people will grab a local copy to do with as they will, and/or remain oblivious to your site completely...
Being a lazy sort, it seemed only right and proper that I should read throught the reports of the previous Arcadia Fellows to see if there were any ideas contained within them that would be amenable to a quick hack or two...
"Mobile OPAC: Staff at Cambridge University Library have observed customers using their camera phones to take pictures of the catalogue results screen, rather than noting class marks on a piece of paper. 50% of respondents at both universities said they take photos of signs, books, etc to save information for later reference." [p8] This maybe lends some sort of post hoc third party justification for my first hack on the Arcadia Mashups Blog: Visual Links - Sharing Links With QR Codes where I posted a quick bookmarklet to show what a QR code on the OPAC might look like and where it might point to, as well as pondering what a library shortcode might look like...
"Mobile OPAC: In the long term libraries could work with their Library Management System supplier (LMS) to create a mobile version of their library catalogue. There is already a mobile application for OCLC’s WorldCat, so libraries who submit their catalogue records to WorldCat could make use of that to pilot the service." [p8-9] I think that the Cambridge University Library Newton catalogue is accessible via WorldCat, so there may be a quick win available there, e.g. producing a WorldCat mobile page that limits results to Cambridge University holdings (if that's possible?). I don't (yet...) know if Newton supports OpenSearch RSS, or whether it's user interface is easily scrapeable, but if so, a quick hack of a prototype web based iPhone/mobile like interface using iUI shouldn't be too hard to do...?
"Less than 16% of Cambridge respondents use their mobile phones to access the internet more than once a week, and only 25% do at the OU." [p10] The report is dated May 2009 -it would be interesting to know if this percentage is increasing, e.g. as mobile phone clients for social networks such as Facebook become increrasingly available, and along with the rise of mobile app stores. There may also be a question of semantics - would a user of a mobile phone application for social network say that they are accessing the internet? Or would they regard the internet as something other - e.g. visiting a web page?
As to how they would like to be able to use their mobiles?
(Note that there's nothing there about the 'note taking' use of camera phones? Though that could be seen as a largely offline use, I guess, even if it is most powerful if tied in to an online reference generating service?)
although opening time information does not appear to be universally available directly through the centralised directory?
So it looks like there may be a quick win there for a simple map based app/web page that included library opening times? A simple SMS text based interface might also be appropriate for delivering library opening time info, though the question remains as to how users would find the number to send the request message to...? [Note to self~: review my old, old thinkiing on this: Micro- and Appropriate Format Information Services]
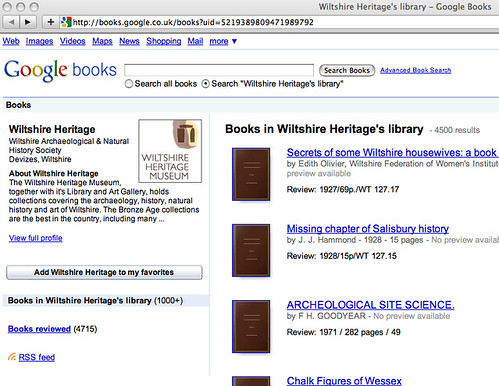
The Wiltshire Heritage Museum library has just gone online with a full digital library created in just 5 months using the controversial Google Books service.
How so? By using the Google Books personal library facility: My Library, which allows you to create a custom search engine limited to searching over the full text of the books you have added to your Google book library.
At the moment there's not a lot of branding on the Wiltshire Heritage page, and the URL is a vanilla rather than redirected one (or even a vanity URL), but the functionality is there...
That said, there is a Google Books API to code against for developing custom services based around this collection. The default RSS feed provides a feed of the books added most recently to the Google books collection.
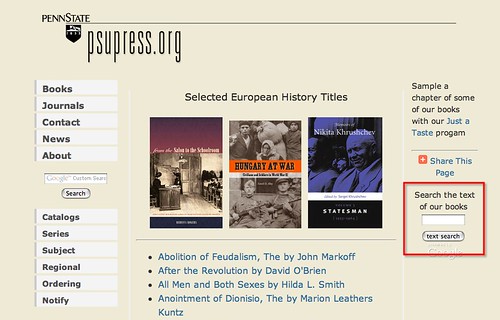
There is also potential for embedding the search facility within the Wiltshire Heritage Library domain using Google's Co-Branded Search facility.
Here's an example of such a cobranded experience, from Penn State University. First, the search box:
The results page can be branded along the top:
For books with a limited or full preview, the preview page can be similarly branded:
In the context of the Cambridge Libraries, I'd have thought that the sheer number of affiliated libraries means that there is at least the potential for running a small trial of this service over some of the holdings from one of the departmental or College libraries? Or maybe not...
Although not a full text search service, LibraryThing's LibraryThing for Libraries service can complement a legacy OPAC with book recommendations and tag based pivot searching around a particular book using the wisdom of the LibraryThing userbase.
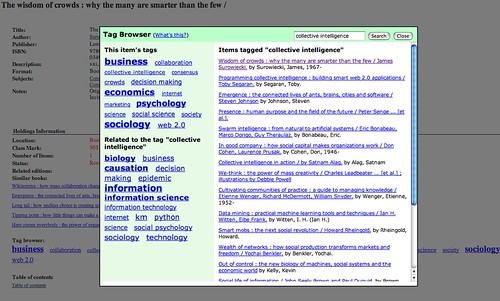
LibraryThing for Libraries is currently being trialled by the OU Library with their Voyager OPAC, as this example of tag based browsing around a particular book result shows:
The Arcadia Project is a three-year project funded by a generous grant from the Arcadia Fund to explore the role of academic libraries in a digital age. A major part of the project is a Fellowship Program which brings interesting people to Cambridge to work on aspects of this very broad subject. We have a project website which serves as the hub for our more formal activities. This blog is an informal space for exchanging ideas, contacts and sources.
Tales from the riverbank
-
I was invited to give an online keynote to the Pedaforum conference in
Finland last week. Their theme was sustainability of practice, so I decided
to lean ...
False GenAI Claims
-
Every so often I tinker with Claude.ai to refactor code. It typically makes
huge claims about how many lines of code it has refactored out, but diffs
rarel...